Prije ili kasnije, svi koji često rade s uredskim programima suočavaju se s tipičnim zadatkom - skenirati tekst iz knjige, časopisa, novina, jednostavno letaka, a zatim te slike prevesti u tekstualni format, na primjer, u Wordov dokument.
Da biste to učinili, potreban vam je skener i poseban program za prepoznavanje teksta. Ovaj članak će raspravljati o besplatnom kolegi iz FineReader-a -Cuneiform (o prepoznavanju u FineReader-u - pogledajte ovaj članak).
Počnimo ...
Sadržaj
- 1. Značajke programa CuneiForm, značajke
- 2. Primer prepoznavanja teksta
- 3. Paketno prepoznavanje teksta
- 4. Zaključci
1. Značajke programa CuneiForm, značajke
 Cuneiform
Cuneiform
Možete ga preuzeti sa web lokacije programera: //cognitiveforms.com/
Program za prepoznavanje teksta s otvorenim kodom. Uz to, radi u svim verzijama Windowsa: XP, Vista, 7, 8, što raduje. Osim toga, dodajte celokupni ruski prevod programa!
Pros:
- prepoznavanje teksta na 20 najpopularnijih svjetskih jezika (u ovaj broj ulaze i engleski i ruski);
- Ogromna podrška za razne print fontove;
- provjeriti rječnik prepoznatog teksta;
- mogućnost uštede rezultata rada na više načina;
- očuvanje strukture dokumenta;
- Velika podrška i prepoznavanje stola.
Protiv:
- ne podržava prevelike dokumente i datoteke (više od 400 dpi);
- Ne podržava direktno određene vrste skenera (dobro, to nije velika stvar, s upravljačkim programima skenera uključen je poseban program za skeniranje);
- dizajn ne sjaji (ali kome treba ako program u potpunosti riješi problem).
2. Primer prepoznavanja teksta
Pretpostavljamo da ste već dobili potrebne slike za prepoznavanje (skenirali ih ili preuzeli knjigu u pdf / djvu formatu na Internetu i uklonili potrebne slike s njih. Za kako to učiniti pogledajte ovaj članak).
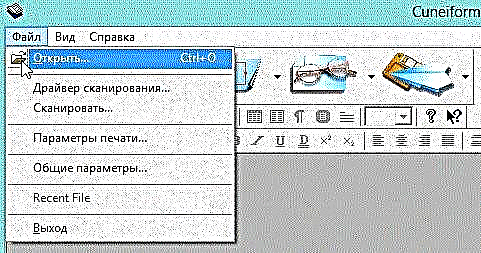
1) Otvorite željenu sliku u programu CuineForm (datoteka / otvori ili „Cntrl + O“).
2) Da biste započeli prepoznavanje - najprije morate odabrati različita područja: tekst, slike, tablice, itd. U programu Cuneiform to se može učiniti ne samo ručno, već i automatski! Da biste to učinili, kliknite na gumb "izgled" u gornjoj ploči prozora.

3) Nakon 10-15 sekundi. Program će automatski istaknuti sva područja sa različitim bojama. Na primjer, područje teksta je označeno plavom bojom. Usput je istakla ispravno i prilično brzo sve oblasti. Iskreno, nisam očekivao od nje tako brzu i korektnu reakciju ...

4) Za one koji ne vjeruju automatskom izgledu, možete koristiti priručnik. Da biste to učinili, postoji alatna traka (vidi sliku ispod), zahvaljujući kojoj možete odabrati: tekst, tablicu, sliku. Pomjerajte, povećajte / smanjite početnu sliku, obrezujte ivice. Općenito, dobar set.

5) Nakon što su sva područja obeležena, možemo pristupiti prepoznavanje. Da biste to učinili, jednostavno kliknite na dugme istog naziva, kao na slici ispod.

6) Bukvalno za 10-20 sekundi. Vidjet ćete dokument u programu Microsoft Word s prepoznatim tekstom. Zanimljivo je da je u tekstu za ovaj primjer naravno bilo grešaka, ali njih je vrlo malo! Štoviše, s obzirom na to kakav je neprimjeren kvalitet bio izvorni materijal - slika.
Brzina i kvaliteta prilično su uporedivi sa FineReader-om!

3. Paketno prepoznavanje teksta
Ova programska funkcija može vam dobro doći kada trebate prepoznati ne jednu sliku, već nekoliko istovremeno. Prečica za pokretanje prepoznavanja serije obično se skriva u startnom meniju.
1) Nakon otvaranja programa, morate kreirati novi paket ili otvoriti prethodno spremljeni. U našem primjeru napravite novi.

2) U sljedećem koraku dajemo mu ime, po mogućnosti onome koje podsjeća na ono što je u njemu pohranjeno šest mjeseci kasnije.

3) Zatim odaberite jezik dokumenta (ruski-engleski), naznačite da li u skeniranom materijalu postoje slike i tablice.

4) Sada morate odrediti mapu u kojoj se nalaze datoteke za prepoznavanje. Usput, što je zanimljivo, program će sam pronaći sve slike i druge grafičke datoteke koje može prepoznati i dodati ih u projekt. Jednostavno morate ukloniti dodatni.

5) Sljedeći korak nije važan - nakon prepoznavanja odaberite što ćete raditi s izvornim datotekama. Preporučujem da odaberete potvrdni okvir "ne radi ništa".

6) Ostaje samo odabrati format u koji će se prepoznati prepoznati dokument spremiti. Postoji nekoliko opcija:
- rtf - datoteka s riječnog dokumenta, koju su otvorile sve popularne kancelarije (uključujući besplatne, poveznicu na programe);
- txt - format teksta, u njega možete spremiti samo tekst, slike i tablice ne mogu biti;
- htm - hipertekst stranice, pogodno ako skenirate i prepoznate datoteke za web lokaciju. Izabrat ćemo je u našem primjeru.

7) Nakon klika na gumb "Završi" započet će proces obrade vašeg projekta.

8) Program djeluje prilično brzo. Nakon prepoznavanja, ispred vas će se pojaviti kartica s htm datotekama. Ako kliknete na takvu datoteku, pokreće se preglednik, u kojem možete vidjeti rezultate. Usput, paket se može spremiti za daljnji rad s njim.

9) Kao što vidite, rezultati djelo je vrlo impresivno. Program je sliku lako prepoznao, a ispod nje se tekst lako prepoznao. Iako je program besplatan, generalno je super!


4. Zaključci
Ako često ne skenirate i ne prepoznajete dokumente, kupnja programa FineReader vjerojatno nema smisla. CuneiForm s lakoćom rješava većinu zadataka.
Sa druge strane, ona takođe ima nedostatke.
Prvo, ima premalo alata za uređivanje i provjeru rezultata. Drugo, kada morate prepoznati puno slika, zgodnije je u FineReaderu odmah vidjeti sve što je dodano projektu u stupcu s desne strane: brzo uklonite nepotrebne, izvršite ispravke itd. I treće, CuneiForm gubi kao prepoznavanje na dokumentima: Moram vam paziti na dokument - urediti pogreške, staviti interpunkcijske znakove, navodnike itd.
To je sve. Poznajete li neki drugi vrijedan program za besplatno prepoznavanje teksta?